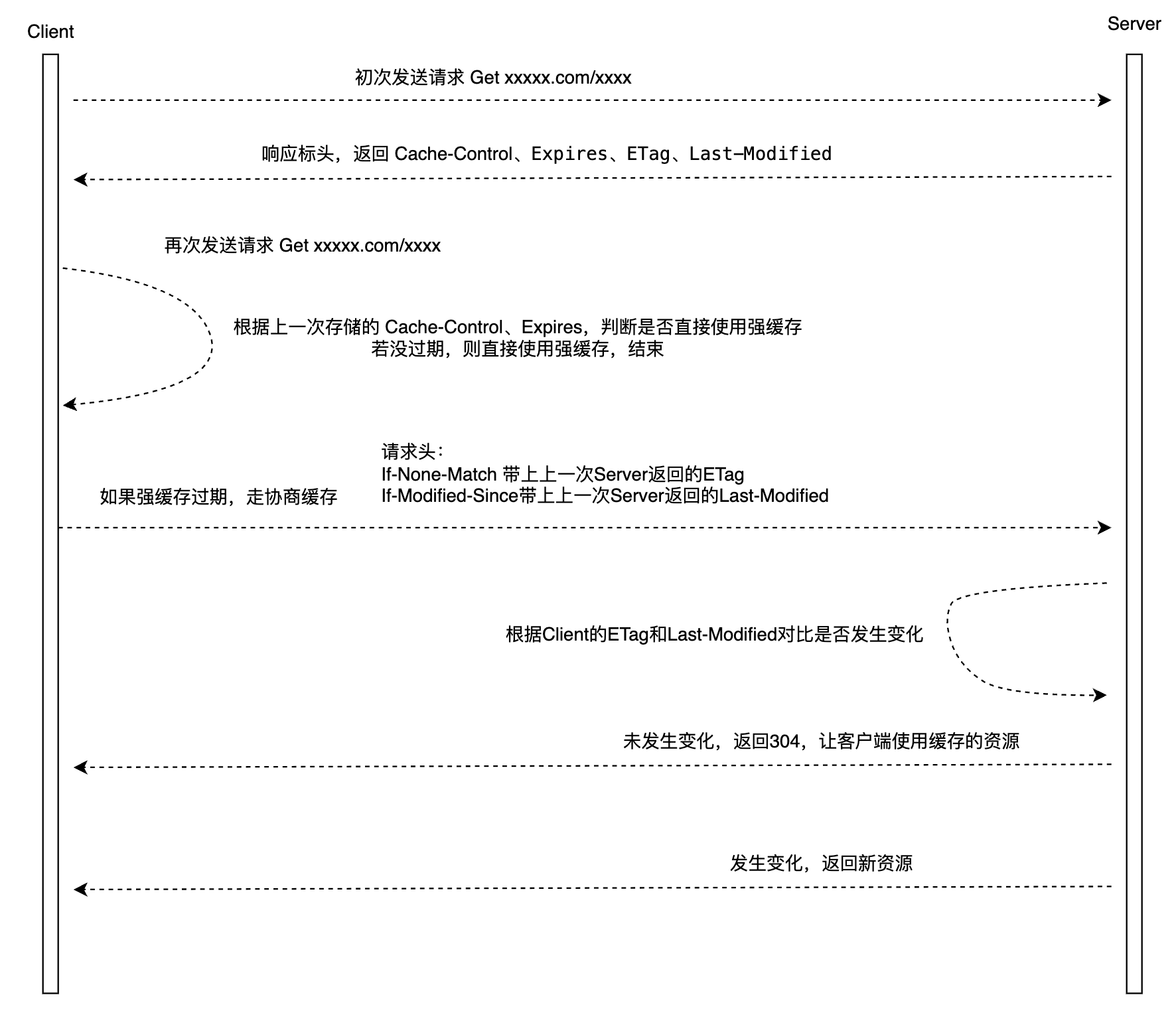
HTTP缓存过程
第一次发送请求 - 服务器响应,响应标头带上Cache-Control、Expires、ETag、Last-Modified
第二次发送请求 - 先根据Cache-Control、Expires判断强缓存是否失效,如果失效,If-None-Match中的上一次ETag和If-Modified-Since中的上一次Last-Modified来判断是否变更,如果没有变更,返回304让浏览器使用本地缓存
强缓存
Cache-Control
Cache-Control 是 HTTP/1.1 中新增的属性,在请求头和响应头中都可以使用,常用的属性值如有:
- max-age:单位是秒,缓存时间计算的方式是距离发起的时间的秒数,超过间隔的秒数缓存失效
- no-cache:不使用强缓存,需要与服务器验证缓存是否新鲜
- no-store:禁止使用缓存(包括协商缓存),每次都向服务器请求最新的资源
- private:专用于个人的缓存,中间代理、CDN 等不能缓存此响应
- public:响应可以被中间代理、CDN 等缓存
- must-revalidate:在缓存过期前可以使用,过期后必须向服务器验证
Expires
Expires 的值是一个 HTTP 日期,在浏览器发起请求时,会根据系统时间和 Expires 的值进行比较,如果系统时间超过了 Expires 的值,缓存失效。
由于和系统时间进行比较,所以当系统时间和服务器时间不一致的时候,会有缓存有效期不准的问题。Expires 的优先级在三个 Header 属性中是最低的。
协商缓存
当浏览器的强缓存失效的时候或者请求头中设置了不走强缓存,并且在请求头中设置了If-Modified-Since 或者 If-None-Match 的时候,会将这两个属性值到服务端去验证是否命中协商缓存,如果命中了协商缓存,会返回 304 状态,加载浏览器缓存,并且响应头会设置 Last-Modified 或者 ETag 属性。
ETag/If-None-Match
ETag/If-None-Match 的值是一串 hash 码,代表的是一个资源的标识符,当服务端的文件变化的时候,它的 hash码会随之改变
Last-Modified/If-Modified-Since
Last-Modified/If-Modified-Since 的值代表的是文件的最后修改时间
如何实现ETag?
Nginx中ETag是如何实现的: 上次修改时间 + content-length
缓存配置
题目:简述你们前端项目中资源的缓存配置策略
题目:现代前端应用应如何配置 HTTP 缓存机制
关于 http 缓存配置的最佳实践为以下两条:
- 文件路径中带有 hash 值:一年的强缓存。因为该文件的内容发生变化时,会生成一个带有新的 hash 值的 URL。前端将会发起一个新的 URL 的请求。配置响应头
Cache-Control: public,max-age=31536000,immutable
- 文件路径中不带有 hash 值:协商缓存。大部分为 public 下文件。配置响应头
Cache-Control: no-cache 与 etag/last-modified
但是当处理永久缓存时,切记不可打包为一个大的 bundle.js,此时一行业务代码的改变,将导致整个项目的永久缓存失效,此时需要按代码更新频率分为多个 chunk 进行打包,可细粒度控制缓存。
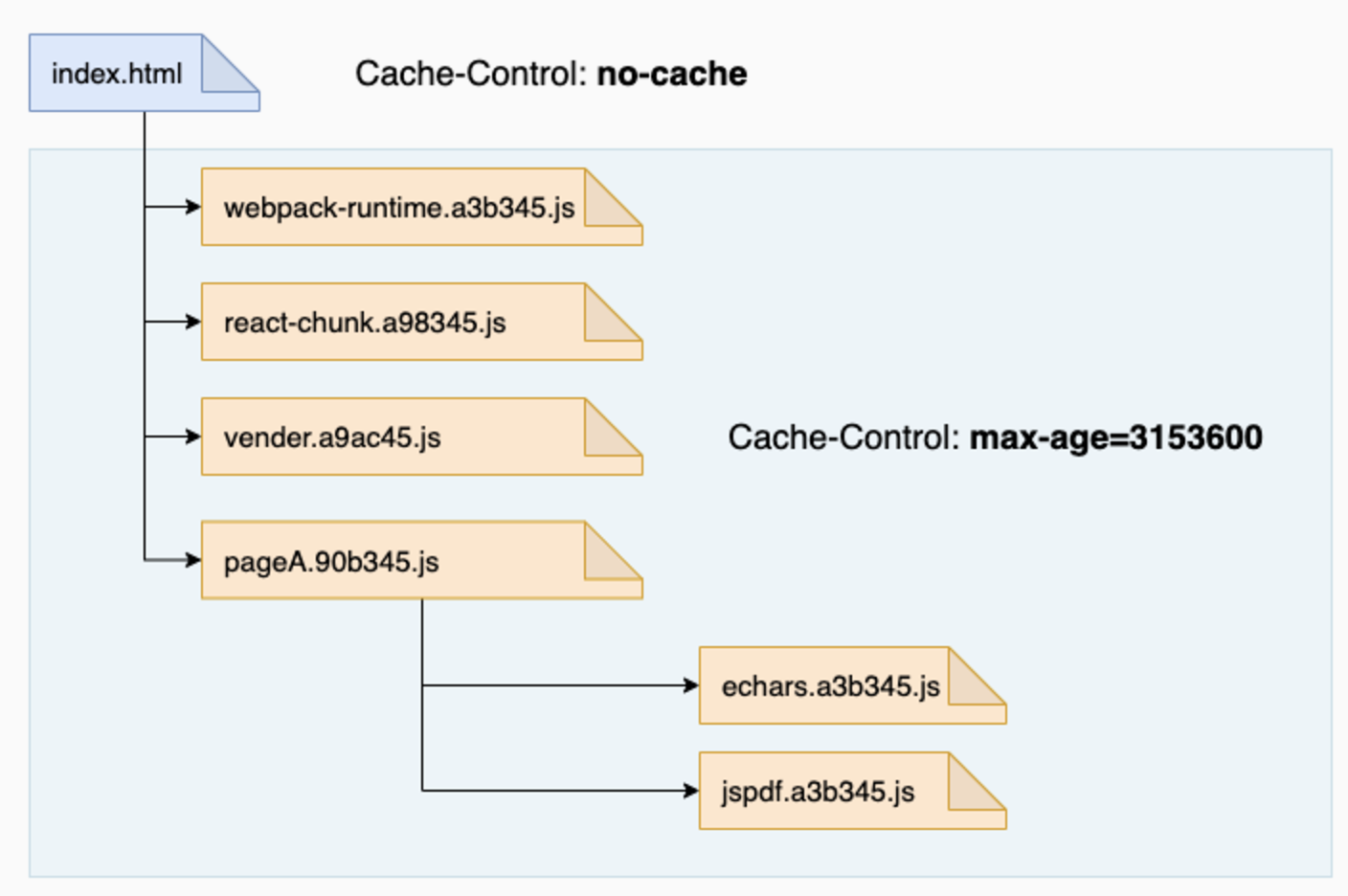
- webpack-runtime: 应用中的 webpack 的版本比较稳定,分离出来,保证长久的永久缓存
- react/react-dom: react 的版本更新频次也较低
- vendor: 常用的第三方模块打包在一起,如 lodash,classnames 基本上每个页面都会引用到,但是它们的更新频率会更高一些。另外对低频次使用的第三方模块不要打进来
- pageA: A 页面,当 A 页面的组件发生变更后,它的缓存将会失效
- pageB: B 页面
- echarts: 不常用且过大的第三方模块单独打包
- mathjax: 不常用且过大的第三方模块单独打包
- jspdf: 不常用且过大的第三方模块单独打包
Nginx配置缓存
通常是通过Nginx来托管静态资源,缓存、跨域等配置也是在Nginx中进行配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| # nginx.conf 核心配置
server {
listen 80;
server_name your-domain.com; # 你的域名
# 1. 静态资源根目录(前端打包后的 dist 目录)
root /usr/share/nginx/html;
index index.html;
# 2. 缓存配置(不同资源不同缓存策略)
location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
expires 7d; # 强缓存:7天
add_header Cache-Control "public, max-age=604800"; # 协商缓存
add_header ETag $etag; # 生成文件唯一标识
# 3. Gzip 压缩(文本资源必开)
gzip on;
gzip_types application/javascript text/css text/html;
gzip_min_length 1k; # 大于1k的文件才压缩
# 4. 防盗链(仅允许自己的域名访问)
valid_referers your-domain.com *.your-domain.com;
if ($invalid_referer) {
return 403; # 非允许域名返回403
}
}
# 5. 单页应用路由适配(history 模式)
location / {
try_files $uri $uri/ /index.html; # 找不到文件时返回 index.html
}
# 6. 重定向到 HTTPS(可选)
return 301 https:
}
# HTTPS 配置(可选)
server {
listen 443 ssl;
server_name your-domain.com;
ssl_certificate /path/to/your/cert.pem; # SSL 证书路径
ssl_certificate_key /path/to/your/key.pem;
# 其余配置和上面一致(根目录、缓存、压缩等)
root /usr/share/nginx/html;
index index.html;
}
|